Aprenda como o Naive Bayes usa probabilidade para classificar dados de forma rápida e eficiente. Veja exemplos e casos de uso no mundo real.
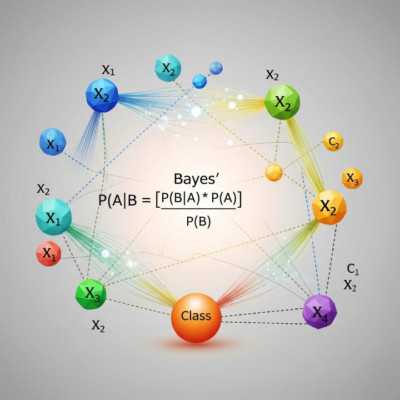
O Naive Bayes é um algoritmo de classificação baseado no Teorema de Bayes, que aplica princípios de probabilidade para prever a classe de um conjunto de dados. Ele assume que as variáveis de entrada são independentes entre si — uma simplificação que, apesar de “ingênua” (naive), funciona muito bem em muitos cenários.
Essa abordagem torna o Naive Bayes extremamente rápido para treinar e aplicar, mesmo em grandes volumes de dados.
Como Funciona o Naive Bayes
O algoritmo calcula a probabilidade de um dado pertencer a cada classe possível e seleciona aquela com a maior probabilidade.
Por exemplo, na filtragem de e-mails, ele estima a probabilidade de uma mensagem ser “spam” com base em palavras-chave, remetente e outros atributos.
Mesmo com a suposição de independência entre variáveis, o Naive Bayes apresenta excelente desempenho em diversos contextos.
Principais Aplicações do Naive Bayes
O Naive Bayes é amplamente utilizado em:
- Classificação de textos (spam vs. não spam, análise de sentimentos).
- Diagnóstico médico (identificação de doenças com base em sintomas).
- Reconhecimento de fala (interpretação de comandos de voz).
- Sistemas de recomendação (classificação de itens com base em histórico de uso).
Vantagens e Limitações do Naive Bayes
Vantagens:
- Treinamento rápido, mesmo com grandes datasets.
- Bom desempenho com dados de alta dimensionalidade.
- Funciona bem mesmo com poucos dados de treino.
Limitações:
- Suposição de independência entre variáveis nem sempre é verdadeira.
- Menos preciso em cenários onde variáveis estão fortemente correlacionadas.
Quando Usar o Naive Bayes em Machine Learning
O Naive Bayes é recomendado quando:
- O volume de dados é grande e o tempo de processamento é crítico.
- O problema envolve classificação de texto ou dados categóricos.
- É necessário um modelo simples e interpretável.
Links Internos Recomendados
- Veja também: SVM – Classificação Precisa com Máquinas de Vetores de Suporte
- Leia mais: KNN – Classificação Simples e Eficaz de Dados
Final

Data Cientist and Data Engineer
- Novo Algoritmo GPT-5.2 da OpenAI - 26 de fevereiro de 2026
- Como a IA Está Transformando Processos nas Empresas - 15 de novembro de 2025
- Data Lake vs Data Warehouse: Qual é a Melhor Solução para Sua Empresa? - 1 de novembro de 2025