
Análise Estatística de Dados Esportivos: como o Machine Learning pode apoiar plataformas de apostas online
Uma aposta injusta? O esporte sempre foi cheio de emoção, rivalidade e imprevisibilidade. Mas, por trás de cada jogo, existe uma quantidade enorme de dados que pode ser analisada com inteligência. Hoje, plataformas de apostas online, empresas de análise esportiva e profissionais de dados usam estatística e Machine Learning para entender padrões, calcular probabilidades e […]
Read More
Como Pequenas Empresas Podem Começar com Inteligência Artificial
Hoje em dia todo mundo fala de Inteligência Artificial. Parece que, se a empresa não estiver usando IA, ela ficou para trás. Mas a verdade é que muita gente ainda olha para esse assunto como algo distante, caro ou complicado demais. Eu penso diferente. Na prática, a Inteligência Artificial não precisa começar com um projeto […]
Read More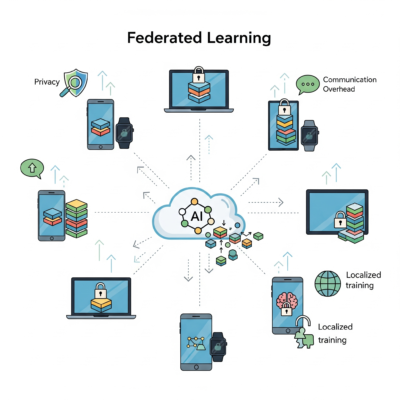
Federated Learning: Treine Modelos sem Compartilhar Dados Sensíveis
Entenda como o Federated Learning permite treinar modelos de IA em dados privados sem centralizá-los. Veja aplicações, vantagens e desafios. O Que é Federated Learning O Federated Learning (Aprendizado Federado) é uma técnica de Machine Learning que permite treinar modelos diretamente nos dispositivos ou servidores onde os dados estão armazenados, sem que seja necessário transferi-los […]
Read More
Redução da Dimensionalidade
Quando Devemos Usar Técnicas de Redução da Dimensionalidade? Quando comecei a me aventurar no mundo da ciência de dados, me deparei com um problemão: datasets gigantescos com dezenas, às vezes centenas, de variáveis. Parece legal ter tanto dado, né? Mas, na prática, isso pode virar uma dor de cabeça. Foi aí que descobri as técnicas […]
Read More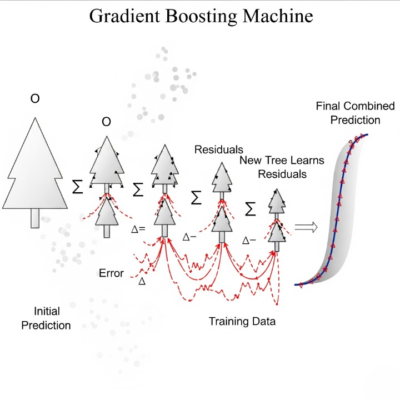
GBM em Machine Learning: Potencialize a Performance dos Seus Modelos
Entenda como o GBM melhora modelos combinando árvores de decisão sequenciais para corrigir erros e aumentar a precisão. Veja exemplos práticos. O Que é o Gradient Boosting Machines (GBM) O GBM (Gradient Boosting Machines) é um algoritmo de ensemble que combina múltiplas árvores de decisão para criar modelos mais precisos. Ele funciona de forma sequencial, […]
Read More
Algoritmos de Machine mais Usados
Principais Algoritmos de Machine Learning que Todo Cientista de Dados Deve Conhecer Quando comecei minha jornada na ciência de dados, confesso que fiquei meio perdido com a quantidade de algoritmos de machine learning por aí. Cada um tem seu jeitão e funciona melhor pra certos tipos de problema. Depois de quebrar a cabeça com vários […]
Read More
Caso de Estudo: Como Reduzi Paradas e Custos na Indústria com Manutenção Preditiva Baseada em Machine Learning
Descubra como desenvolvi um projeto de manutenção preditiva que reduziu paradas não programadas em 30% e custos operacionais em uma indústria metalúrgica. 1. O Desafio que o Cliente Apresentou No início de 2025, fui procurado por uma indústria metalúrgica de médio porte que enfrentava um problema crítico: paradas frequentes nas linhas de produção devido a […]
Read More
Serviços de Ciência de Dados no Brasil: o que são e como contratar?
Empresas que tomam decisões com base em dados estão saindo na frente no mercado — e isso não vale apenas para as grandes. Cada vez mais, médias e pequenas empresas no Brasil estão investindo em ciência de dados para entender melhor seus clientes, reduzir desperdícios e prever cenários de forma inteligente. Mas afinal, quais são […]
Read MoreAntecipe o Futuro com Modelos Preditivos
Antecipe o Futuro com Modelos Preditivos Baseados em Machine Learning Você já pensou em prever comportamentos dos seus clientes? Saber quando eles vão comprar, cancelar um serviço, ou até mesmo quais produtos terão maior demanda nos próximos meses? A resposta para isso está no uso de modelos preditivos com Machine Learning. São algoritmos treinados com […]
Read More
MLflow: A Chave para Experimentos de Machine Learning
MLflow: A Chave para Experimentos de Machine Learning Organizados e Reproduzíveis Trabalhar com Machine Learning é um processo dinâmico e cheio de desafios. A cada novo experimento, testamos diferentes combinações de hiperparâmetros, ajustamos arquiteturas e refinamos modelos para obter os melhores resultados. No entanto, sem um bom controle e organização, podemos facilmente perder o rastreamento […]
Read More