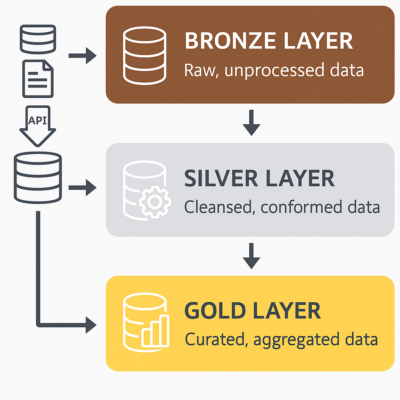
Camadas Bronze Silver e Gold: O Coração da Engenharia de Dados Moderna
Quando comecei a trabalhar com engenharia de dados, uma das primeiras estruturas que aprendi — e que até hoje levo para todos os meus projetos — foi o conceito das camadas Bronze, Silver e Gold. Pode parecer só um “jeito bonito” de nomear tabelas, mas a verdade é que essa organização faz toda a diferença na hora de estruturar dados de forma confiável, reutilizável e escalável dentro de uma empresa.
Neste artigo, quero te explicar, de forma bem simples e prática, o que significa cada uma dessas camadas e por que elas são tão importantes dentro de qualquer pipeline de dados moderno.
O que são as camadas Bronze, Silver e Gold?
Essas três camadas são uma forma de organizar os dados em etapas, dentro do processo de engenharia de dados. Elas ajudam a definir o nível de “tratamento” que os dados receberam e para que tipo de uso eles estão prontos.
Essa estrutura é usada em arquiteturas de Data Lake, Lakehouse e também no Microsoft Fabric, Databricks, AWS, Google Cloud e outras plataformas de dados.
Vamos entender cada uma delas:
🟫 Bronze Layer – A camada bruta (raw)
Essa é a primeira parada dos dados. Aqui, os dados são armazenados exatamente como vêm da fonte. Sem nenhum tratamento, sem padronização, sem limpeza. Pode vir do banco de dados do sistema, de arquivos CSV, APIs, logs de sistemas, e por aí vai.
Exemplo prático:
Imagine que você tem um sistema de vendas online. Na camada Bronze, você simplesmente armazena todos os pedidos do dia, com erros de digitação, campos nulos, formatações diferentes… tudo como está.
💡 Por que isso é útil? Porque serve como backup histórico confiável. Caso precise voltar e revisar algo da origem, a Bronze é sua garantia.
⚪ Silver Layer – A camada tratada (cleaned)
Aqui os dados começam a ganhar “forma”. Na camada Silver, a gente faz a limpeza e padronização: remove duplicidades, trata erros, transforma formatos (por exemplo, data no formato padrão), e começa a cruzar dados entre diferentes tabelas.
Exemplo prático:
Voltando ao sistema de vendas: na Silver, você já juntou os dados de pedidos com os dados dos clientes. Corrigiu campos vazios, ajustou o nome dos produtos, validou o CPF, formatou as datas.
💡 Essa camada é ideal para análises exploratórias e desenvolvimento de modelos de Machine Learning. Os dados já são confiáveis, mas ainda não estão com regras de negócio complexas aplicadas.
🟡 Gold Layer – A camada analítica (curated)
Agora sim, os dados estão prontos para serem consumidos! Na camada Gold, a gente aplica as regras de negócio, cria métricas, faz agregações e prepara os dados para consumo direto por dashboards, relatórios ou APIs.
Exemplo prático:
Na Gold, você tem um painel com Faturamento por mês, Ticket médio por canal de venda, Margem de lucro por produto, entre outras métricas. Todos esses dados vêm da camada Silver, mas com cálculos aplicados e estruturados para responder perguntas do negócio.
💡 Essa camada é o que o CEO, o time comercial ou o financeiro vai olhar nos dashboards.
Por que essa organização faz diferença?
Quando usamos essa estrutura em um projeto, ganhamos clareza, controle e qualidade. Aqui vão alguns dos principais benefícios para a empresa:
- ✅ Governança dos dados: Cada camada tem um propósito claro. Isso evita bagunça e dados desencontrados.
- ✅ Escalabilidade: Novas fontes de dados podem ser inseridas na Bronze e, aos poucos, tratadas e promovidas às camadas superiores.
- ✅ Performance: Dados bem organizados consomem menos recursos de processamento e são mais rápidos de consultar.
- ✅ Segurança e rastreabilidade: Se algo estiver errado na camada Gold, é só voltar nas camadas anteriores e encontrar o ponto de falha.
- ✅ Agilidade nas análises: O analista ou cientista de dados não precisa reinventar a roda toda vez. Ele já pega os dados prontos na camada certa.
E se eu não usar essas camadas?
Se você trabalha com dados e não usa esse modelo, provavelmente está misturando tudo em uma tabela só: dado sujo com dado tratado, campo calculado com campo original. Isso dificulta manutenção, aumenta o risco de erro e torna os projetos mais lentos.
Por isso, a adoção desse padrão é hoje uma prática consolidada na engenharia de dados moderna.
Inclusive, em projetos aqui do Ciência e Dados, eu já implementei essa arquitetura com excelentes resultados. E sempre que uso, consigo mostrar para o cliente como isso melhora a qualidade das decisões com base em dados.
Conclusão
Se você quer trabalhar (ou já trabalha) com engenharia de dados, precisa dominar esse conceito. Bronze, Silver e Gold não são só nomes bonitinhos — são a base para que a informação certa chegue na hora certa, na mão da pessoa certa.
Se você é dono de empresa, gerente, analista ou profissional da área de dados e quer entender melhor como montar essa arquitetura, me chama! Eu posso te mostrar, na prática, como isso se encaixa na realidade do seu negócio.
👉 Acesse mais conteúdos como esse no meu blog
📩 Ou me chame para uma consultoria personalizada.

Data Cientist and Data Engineer
- Novo Algoritmo GPT-5.2 da OpenAI - 26 de fevereiro de 2026
- Como a IA Está Transformando Processos nas Empresas - 15 de novembro de 2025
- Data Lake vs Data Warehouse: Qual é a Melhor Solução para Sua Empresa? - 1 de novembro de 2025