Aprenda como o DBSCAN agrupa dados complexos sem precisar definir o número de clusters. Ideal para padrões irregulares e detecção de outliers.
O Que é o DBSCAN
O DBSCAN (Density-Based Spatial Clustering of Applications with Noise) é um algoritmo de aprendizado não supervisionado usado para encontrar clusters em conjuntos de dados com formas irregulares e com ruído.
Ao contrário de métodos como o K-Means, o DBSCAN não exige que o número de clusters seja definido antecipadamente e é capaz de identificar outliers automaticamente.
Como Funciona o DBSCAN
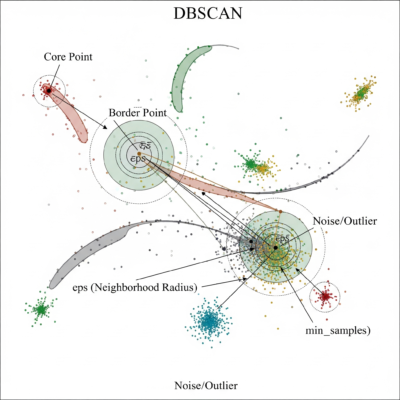
O algoritmo se baseia em dois parâmetros principais:
- ε (eps): distância máxima entre dois pontos para que sejam considerados vizinhos.
- minPts: número mínimo de pontos para formar um cluster.
O DBSCAN classifica cada ponto como:
- Ponto central – tem vizinhos suficientes.
- Ponto de borda – está próximo de um ponto central, mas tem poucos vizinhos.
- Ruído – não pertence a nenhum cluster.
Principais Aplicações do DBSCAN
- Detecção de anomalias em dados financeiros.
- Análise de tráfego e geolocalização.
- Agrupamento de dados espaciais em GIS.
- Reconhecimento de padrões complexos em imagens e sinais.
Vantagens e Limitações do DBSCAN
Vantagens:
- Não requer número de clusters pré-definido.
- Lida bem com clusters de formas irregulares.
- Identifica automaticamente pontos de ruído.
Limitações:
- Sensível à escolha dos parâmetros ε e minPts.
- Pode ter desempenho ruim em dados com densidade variável.
Quando Usar o DBSCAN
O DBSCAN é indicado quando:
- O formato dos clusters não é esférico.
- Há presença de outliers que precisam ser identificados.
- Não se sabe previamente quantos grupos existem nos dados.
Links Internos Recomendados
- Veja também: PCA – Redução de Dimensionalidade em Machine Learning
- Leia mais: SVM – Classificação Precisa com Máquinas de Vetores de Suporte
CTA Final

Josemar Prates da Cruz at Ciencia e Dados
Cientista e Engenheiro de Dados
Data Cientist and Data Engineer
Data Cientist and Data Engineer
Latest posts by Josemar Prates da Cruz (see all)
- Novo Algoritmo GPT-5.2 da OpenAI - 26 de fevereiro de 2026
- Como a IA Está Transformando Processos nas Empresas - 15 de novembro de 2025
- Data Lake vs Data Warehouse: Qual é a Melhor Solução para Sua Empresa? - 1 de novembro de 2025