
Novo Algoritmo GPT-5.2 da OpenAI
Minha Experiência com o Novo Algoritmo GPT-5.2 da OpenAI e o Impacto no Mundo da Ciência de Dados Nos últimos anos eu venho acompanhando de perto a evolução dos modelos da OpenAI. Desde as primeiras versões do GPT, que já eram revolucionárias, até o mais recente GPT-5.2, tenho visto um salto enorme em capacidade, inteligência […]
Read More
Como a IA Está Transformando Processos nas Empresas
Automação Inteligente: Como a IA Está Transformando Processos nas Empresas Você já parou pra pensar em quanto tempo sua empresa perde com tarefas repetitivas? Enviar relatórios, aprovar planilhas, conferir dados, responder e-mails… tudo isso consome energia e tempo que poderiam ser usados pra criar e inovar.Mas a boa notícia é: a automação inteligente veio pra […]
Read More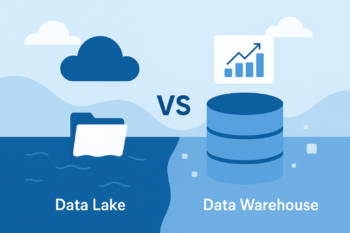
Data Lake vs Data Warehouse: Qual é a Melhor Solução para Sua Empresa?
Data Lake vs Data Warehouse Quando o assunto é armazenamento e análise de dados, uma dúvida aparece em praticamente toda empresa:👉 “Devo investir em um Data Lake ou em um Data Warehouse?” Se você também já se perguntou isso, fique tranquilo. Eu vou te explicar, de forma simples e direta, as diferenças entre essas duas […]
Read More
Data Contracts: o elo entre Engenharia de Dados e Governança
🧩 Data Contracts: o elo entre Engenharia de Dados e Governança Se você trabalha com dados, já deve ter passado por isso: o time de engenharia muda o formato de uma tabela sem avisar, e de repente o dashboard do pessoal de BI quebra. 😬Ou então, o modelo de Machine Learning começa a dar resultados […]
Read More
Augmented Analytics em Data Science: Insights Inteligentes com IA e Visualização
Descubra como o Augmented Analytics combina inteligência artificial e visualização para gerar insights rápidos e precisos. Veja aplicações e benefícios. O Que é Augmented Analytics O Augmented Analytics é uma abordagem que utiliza inteligência artificial e aprendizado de máquina para automatizar tarefas de análise de dados, como preparação, descoberta de padrões e geração de insights.Essa […]
Read More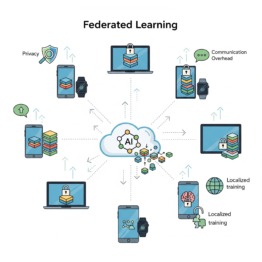
Federated Learning: Treine Modelos sem Compartilhar Dados Sensíveis
Entenda como o Federated Learning permite treinar modelos de IA em dados privados sem centralizá-los. Veja aplicações, vantagens e desafios. O Que é Federated Learning O Federated Learning (Aprendizado Federado) é uma técnica de Machine Learning que permite treinar modelos diretamente nos dispositivos ou servidores onde os dados estão armazenados, sem que seja necessário transferi-los […]
Read More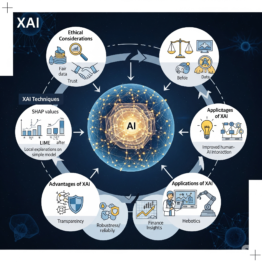
Explainable AI e Ética: Transparência e Justiça em Modelos de Machine Learning
Aprenda como tornar modelos de IA mais transparentes e éticos usando Explainable AI. Veja técnicas, vantagens e aplicações em diversos setores. O Que é Explainable AI e Por Que Ela é Importante A Explainable AI (IA Explicável ou XAI) é um conjunto de métodos e práticas que tornam os resultados de um modelo de Machine […]
Read More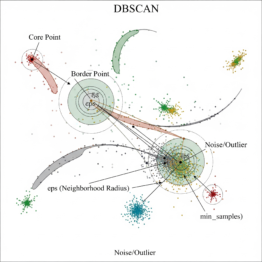
DBSCAN: Agrupamento de Dados Baseado em Densidade
Aprenda como o DBSCAN agrupa dados complexos sem precisar definir o número de clusters. Ideal para padrões irregulares e detecção de outliers. O Que é o DBSCAN O DBSCAN (Density-Based Spatial Clustering of Applications with Noise) é um algoritmo de aprendizado não supervisionado usado para encontrar clusters em conjuntos de dados com formas irregulares e […]
Read More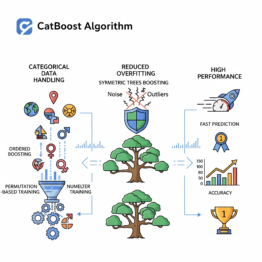
CatBoost em Machine Learning: Otimize Modelos com Dados Categóricos
Descubra como o CatBoost lida com dados categóricos de forma nativa, reduz overfitting e entrega alta performance. Veja aplicações práticas. O Que é o Algoritmo CatBoost O CatBoost é um algoritmo de gradient boosting desenvolvido pela Yandex, projetado para lidar de forma eficiente com variáveis categóricas sem a necessidade de conversões manuais como one-hot encoding. […]
Read More
Redução da Dimensionalidade
Quando Devemos Usar Técnicas de Redução da Dimensionalidade? Quando comecei a me aventurar no mundo da ciência de dados, me deparei com um problemão: datasets gigantescos com dezenas, às vezes centenas, de variáveis. Parece legal ter tanto dado, né? Mas, na prática, isso pode virar uma dor de cabeça. Foi aí que descobri as técnicas […]
Read More